02/07/2024
A working group in the area of data reliability and security at Università Politecnica delle Marche (UNIVPM) is working on the design and development of a blockchain-based platform to certify data. Special focus is given to the certification of the different processes involved in the case study related to mussel aquaculture.
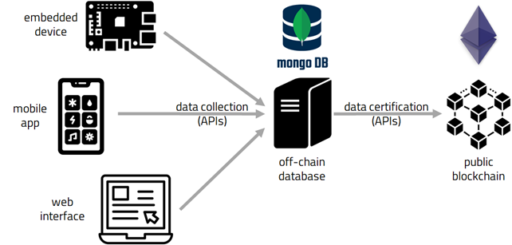
The designed architecture is based on a central component, consisting of an off-chain server equipped with storage capacity for the data to be collected and certified, as well as capacity to execute the cryptographic functions required for their certification. Such a central server is expected to perform the following core functions:
Once the collection and blockchain-based certification of data has been carried out, anyone who comes into the possession of the certified data and the related certification information can verify its correctness directly. This can be done by querying the central server again, or in an entirely decentralized manner, via functions executed locally.
The data collected during the mussel aquaculture case study will be used to test the blockchain-based platform for certifying data. The productive cycle of mussels can be affected by several factors that can represent potential sources of food loss. The acquisition of data from different variables during mussel farming can represent a suitable solution to provide data to monitor the productive cycle and possibly prevent and minimize food loss. However, this process is often endangered by the integrity of the data. In fact, data can be modified or purposely deleted, or crucial information can be lost due to technology malfunctions.. For this reason, there is a crucial need for an efficient and secure way to store and certify data, aiming for data integrity and availability.

The aim is to address the problem of certification and data traceability by identifying an architecture that can exploit the inherent advantages of distributed ledger technologies.
The proposed innovative architecture is based on the use of Merkle trees for organizing pieces of information. The primary goal of this approach is to limit the number of blockchain transactions to be generated, making the certification process more efficient and cost-effective. The idea is to independently consider data coming from different sources and organize them into data structures called Merkle trees. Merkle trees are data-compressing structures where the data to be certified are the leaves. These leaves are hashed consecutively using a hashing function (e.g., SHA256) until the tree’s root, known as the Merkle root, is reached. The resulting hash digest is a single string representing all the leaves in a compressed way and will therefore be the only data stored on the blockchain.
Since hashing is not invertible, verifying that information has not been modified after certification requires extracting a set of node values from the tree to test data integrity. Using the so-called Merkle Proof, one can demonstrate that data in a leaf have not been modified.
The certification process is summarized in the next figure. Initially, data that need to be certified are grouped together in a waiting queue and, after a pre-defined amount of time, the certification process begins. Basically, these grouped data are used as leaves to build the Merkle Tree and the Merkle root is computed. While the tree is stored in an off-chain database, the Merkle root is sent to the blockchain through a transaction. Transaction information is stored in the off-chain database as well, together with all the information that allows the verification process (e.g., the Merkle proof).
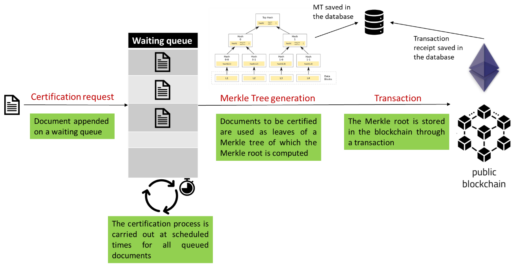
When a user needs to verify some data, the proof is extracted from the off-chain database. Then, the transaction that contains the in-chain root needs to be located in order to start the actual verification function, which includes the following operations:
Users will have the possibility to upload data and to verify them through a friendly interface that will show, for example, if data are in queue or certified, or if the considered data has maintained their integrity or not. An example of a preliminary prototype of this application for the mussels aquaculture case study is shown in the next figures.
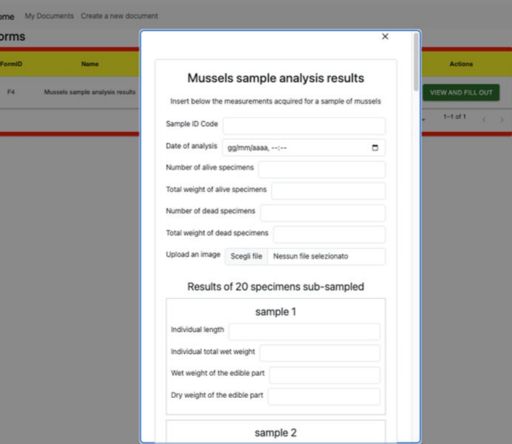
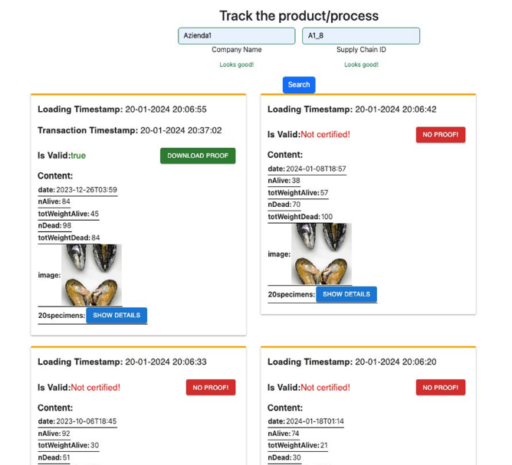

This project has received funding from the European Union’s Horizon Europe research and innovation program, under Grant Agreement: 101084106. Views and opinions expressed are however those of the authors only and do not necessarily reflect those of the European. Neither the European Union nor the granting authority can be held responsible for them.
FOLOU is a proud partner of the Biorefine Cluster Europe.


Copyrights © 2026 | Folou.eu Cookie & Privacy Policy Webdesign & Development by ALYS